Microsoft Case Study

In this case study, we present the process that Localex Team implemented in order to successfully complete one of our Microsoft MT Post-Editing projects. The case study will cover mainly:
- project scope and volume,
- task definitions and guidelines,
- workflow design,
- productivity, management and automation tools,
- challenges and overcome methods,
- overall findings and learnings.

The tools, processes and methods used for this project are by no means restricted to a post-editing project, but could be used for any project involving the outsourcing of tasks to remotely-located individuals.
Case Details
Our client was looking for a reliable partner to localize their IT related contents into various languages in order to expand their customer base and make their products more competitive in foreign markets. They needed a single trusted provider who could take care of their multilingual projects, and manage the post-editing process of machine-translated outputs.
We benefit from a set of post-editing rules prepared by localization industry organizations, which describe in detail the goals of the task and instruct post-editors on how to work on machine-translated output.
All linguists work remotely, accessing post-editing assignments through a cloud-based workflow automation ecosystem.
Machine translated outputs are reviewed by human post-editor teams. Additional quality control is performed by the quality control team at Localex.
- Collaborative action with +300 linguists.
- Project management team of 4 tech-savvy people.
- Quality assurance team of 4 dedicated people.
- MT Knowledge.
- Domain Knowledge.
- Linguistic Knowledge.
- Practical experience with MT post-editing.
- Scientific knowledge on computer science.
- Academic background on machine translation and machine learning.
- Extensive knowledge and experience of managing remote working teams.
- Industry practice on various file types.
- Post-edit large volumes of content.
- Meet tight release schedules.
- Reduce localization costs.
- Manage different quality expectations.
- Work with +300 linguists.
Samples

-
Challenging File Formats
.vtt, .srt, .ts, .ttml, .xlf, .oft, .pptx etc.
-
Challenging Contents:
subtitles for product descriptions and help center,
IT-related technical materials,
marketing materials,
e-mails.
-
Language Pairs:
English (USA) into Turkish, Chinese (Simplified), Spanish (Spain), French (France), Japanese, German (Germany), Korean, Russian, Italian, Portuguese (Brasil), Chinese (Traditional, Taiwan), Indonesian, Vietnamese, Romanian (Romania), Slovenian, Serbian (Latin), Croatian, Bulgarian, Latvian, Arabic, Polish, Greek, Czech, Hungarian, Hebrew, Malay, Thai, Filipino, Dutch, Swedish, Sinhalese, Lithuanian
-
Where Do We Find This Many People?
We work with both in-house and trusted freelance language professionals. However, for a project this big, we needed to expand our teams to 20+ linguists for some languages and to 100+ linguists in total.
Thanks to our translation technology partner Smartcat’s 250,000-strong marketplace, we were able to quickly find new post-editors and add them to the translation process.
Task Definitions and Guidelines
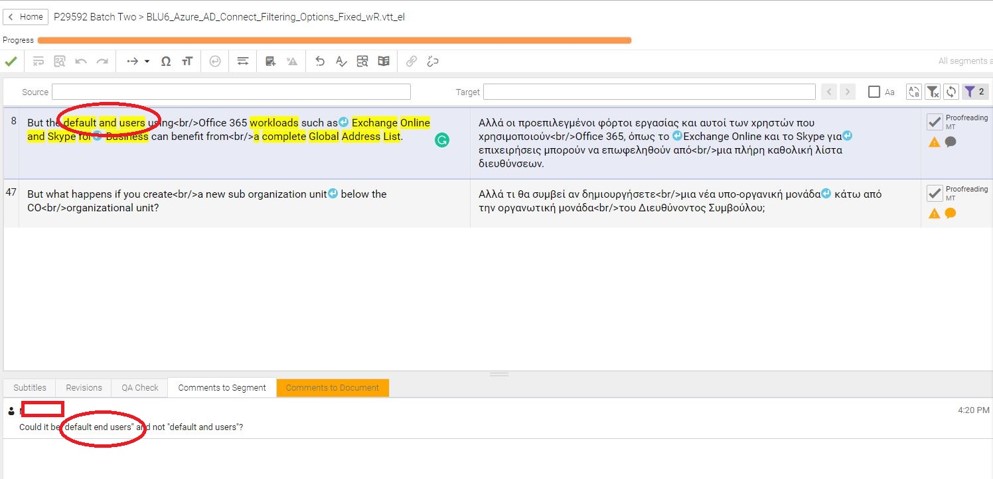
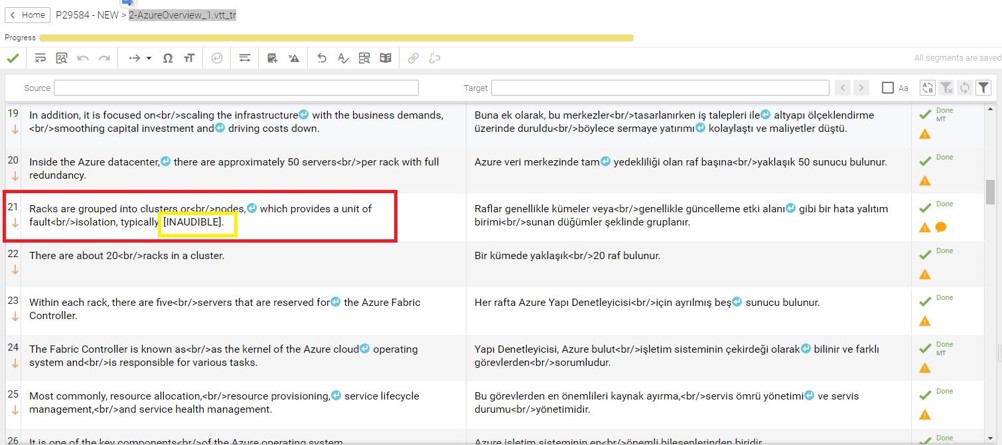
- Review process is driven by “comprehensibility”.
- Pre-process focuses on reducing edits required.
- Linguists focus on improving key information.
- Quality evaluation through practical LQA tasks.
- Terminology is important.
- Feedback and query loop is crucial.
Using these guidelines, our post-editor team learn to make only necessary changes to the MT output by;
- adding meaning that is missing from the MT output.
- removing machine generated errors.
- reviewing words, terms and phrases, and making amendments when the original placement obscures the meaning of the text.
We expect from our linguists for;
- being comprehensible (i.e. an end-user understands the content of the message).
- accurate (i.e. it communicates the same meaning as the source text).
- stylistically fine, though the style may not be as good as that achieved by a native-speaker human translator.
Therefore they;
- aim for grammatically, syntactically and semantically correct translation,
- ensure that key terminology is correctly translated and that untranslated terms belong to the client’s list of “Do Not Translate” terms,
- ensure that no information has been accidentally added or omitted,
- edit any offensive, inappropriate or culturally unacceptable content,
- use as much of the raw MT output as possible,
- apply basic rules regarding spelling, punctuation and hyphenation.
- ensure that formatting is correct.
Workflow
Automation
Linguists are also able to check the status of their progress in order to manage their time more efficiently.
- Guidelines and instructions were created and centralized across all client’s global projects, shared with all localization team via Smartcat project page and updated 24/7.
- Before launching the project, source contents were preprocessed. Important technical changes were applied to improve the quality, consistency and “readability” of the contents.
- Important comments were added to Smartcat before the kick-off.
- The source texts were uploaded to Smartcat Ecosystem and subcategories were created for each of the target languages.
- Thanks to the search and filter options of Smartcat Marketplace, post-editors were selected and multiple invitations were sent with ease.
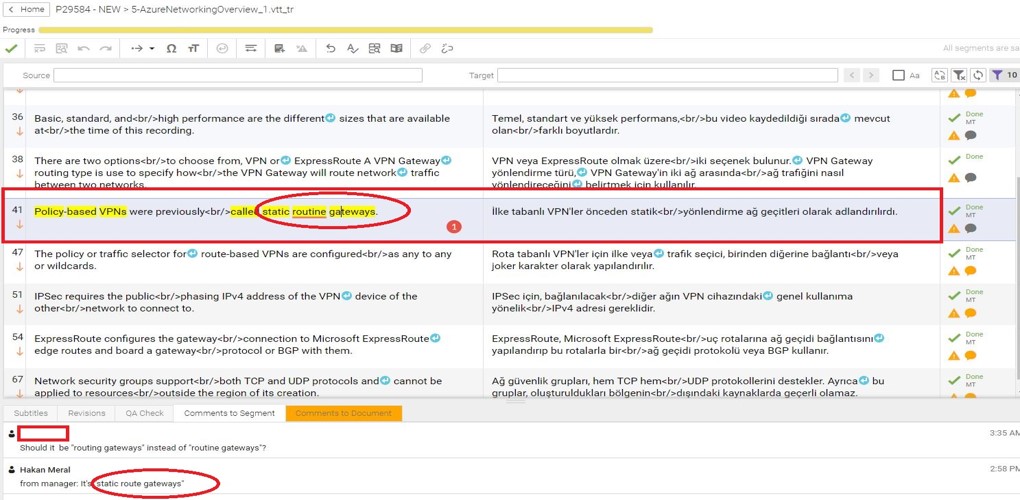
- Questions and comments of the vendors were monitored via Smartcat Chat and Comment to Document feature 24/7.
- Since the deadline was pretty tight for such a big-scale project, more than 20 linguists worked on the files for each language pair.
- Different linguists working for the same file started to communicate via Smartcat comments section to ensure quality.
- The project was completed right on time after the last step of quality assurance.
- The first stage of quality assurance is the quality of the machine translated output. To ensure this, we applied pre- and post- linguistic engineering processes to the workflow.
- Post-editor’s goal is to make edits on the MT output to ensure quality by checking the meaning, putting the tags in their appropriate places and correcting the machine generated errors.
- In addition, a number of automatic and manual quality control mechanisms are in place at Localex during the editing process to catch careless errors or alert QA Team to potential problems.
- QA Team also implements the spot-checks in the files daily, and provide feedback to post-editors accordingly.
Pre-processing
The source files have be to pre-processed by our developer to make them localization friendly.
Post-processing
After the localization process over, the target files have to be post-processed to make them work on the client’s environment again.
Problem: Source files (xlf) are structurally not localization-friendly.
- The segmentation problem and the complex tag structure.
- Extremely long segments.
- On average, there are more than 2500 segments that are longer than 500 characters per language.
- Content has complicated tag structure; i.e. inline tags, markup tags, and placeholders.
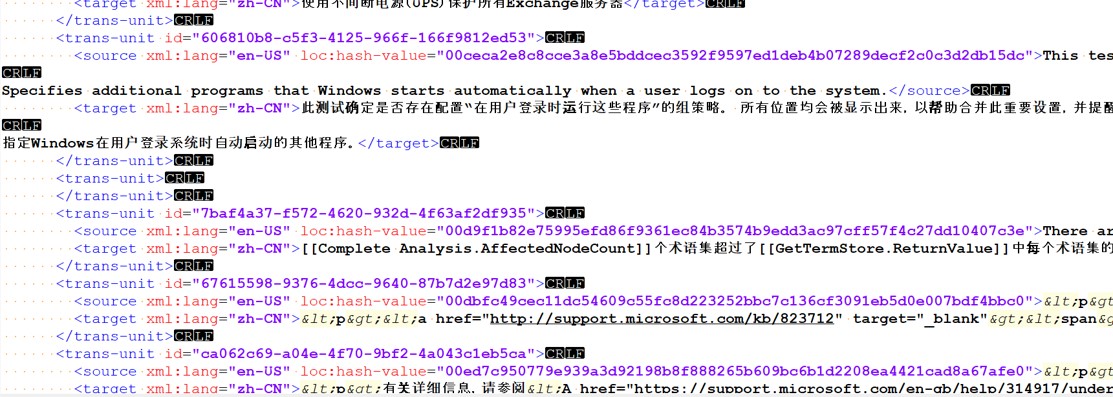



- Xliff is a standard format customized from .xml and that’s why different tools provided the same results. It’s also not so easy to modify segmentation as the output file might be corrupted.
- We offered .xml parsing method to extract the source content and this enabled us to modify the source content accordingly.
- Each of the source segments in the .xlf files are extracted using an .xml parser and saved with their unique trans-unit IDs. These ID lines are not included in the translation production step.
- We could perform some normalization tasks on the content. Unnecessary line breaks are removed, tags are hidden, and segments are re-segmentated. The original pattern was preserved including segmentation, line breaks, whitespace characters, tag contents, URLs and the placeholders within double brackets.
Linguistic Engineering
Custom Placeholders
- As you can see, there are some custom placeholders like {digit}, {$rn}, and $}>. This helped us to preserve original format of the TUID source content.
- Like performed for TS files, the method was tested using the pseudo-translation process and we asked from client to check if the pseudo-translated output files are functionally acceptable. Once we received confirmation, we initiated the actual production phase.
Detailed QA process requirement
Production phase was followed by QA 1, import back, and QA2 steps. Within first QA step, team mainly focused on linguistic checks and the custom placeholders which required custom checklist items. Afterwards the translated output was imported back to their intended locations in the original files.
- Efficient scalability: 3.4 Mn words, 6 languages, 10 days.
- High-quality translations.
- Translation productivity increase 30-40% (5-8K words/day).
- 91% linguist satisfaction with the project.
- Reduced project costs: 35-40% savings.
- Minimal client investment.
- High-tech workflow automation.
- Seamless communication.
- Ongoing improvement through feedback from 300+ linguists.
- New data to train machines.
- New integration processes and platforms.
Testimonials
Localex as a partner has always been trustworthy, exact, professional, and prompt. I can always be sure that a translation project sent to Localex will always be handled promptly and the turnaround time is more than acceptable. Localex uses a wide spectrum of CAT tools and has a linguist pool that can translate and review all kinds of fields of texts.
We share the trainings that we have planned with 44 countries and at the same time use training coming from those countries. Localex is our most important partner in this operation with its speed in our process of professionalization for training, the quality of its work, and its technological infrastructure. With a great peace of mind, we benefit from Localex for the translation of all training documentation as they are well aware of how important eye health is.
There are three main benefits of working with Localex: Good communication, quality translations, and on-time delivery without exception. These are exactly what I, as a customer, am looking for and I can say without a doubt that Localex is one of the best agencies I have worked with.
The fact that each job is confirmed within minutes, cost is also confirmed before the job is started, and on-time delivery occurs every time provides me with peace of mind. I can be sure that the job is not missed, volume or cost is not out of range, and that I will have it when I need it, without needing to send other reminders.
Besides the obvious benefits, good quality translations also mean that I am saving time. We are using internal, native-speaking proofreaders who are also specialists in marketing/the industry. Changes they make are extremely rare and these are mostly preferential. This is not a small thing for such a large volume of translations we do together with Localex, especially considering that we have a lot of technical content. If the proofreader just confirms the translation is okay, this means I don’t have to send other emails for corrections and wait for them to be implemented.
Congratulations to the management and translators for providing such overall quality and a professional service! I would highly recommend this agency to anyone!
Localex is a translation agency that efficiently communicates with its translators and offers highly competitive unit rates compared to the market. Working with thoughtful individuals who care humanitarian values and do not compromise from professionalism ensures that you as a translator have the comfort of just focusing on your job and not having to worry about anything else. The conveniences provided to the translator at Localex are not just limited to these. The computer-assisted translation tools help you work easier and save time by ensuring that the task is done in an effective and productive manner. I would recommend working with Localex to all translators looking for an expert and trusted company where they can work on long-term projects.
Professionalism: check; fair pricing: check; impeccable humor: check. A ‘translator heaven’ that any professional translator should work with… Equip yourself with your best attitude, best translation skills and a good sense of humor, you will not regret a single second that you work with Localex.
Localex, our favourite Turkish language service provider. We are very satisfied with their punctual deliveries, friendly and reliable services and their kind and helpful staff. Keep it up!
LOCALEX is our very reliable Turkish language provider and we have been working together for around 5 years already. The project management team is very responsive, professional and reliable as well as the linguists they are working with. The services provided by LOCALEX has always been of high quality, rendered in a timely fashion even in the case of tight deadlines. We highly value our collaboration and we hope it will continue for the foreseen future.
I started my collaboration with Localex in April 2019, as post-editor. Over the past months, I had the chance to collaborate with them in several projects, in the fields of translation, editing, post-editing and proofreading. I have always enjoyed working with this Company: the members of the Localex team are always extremely friendly, hardworking and reliable and it is possible to see how fast this Company is growing. I hope this is only just the
beginning of our collaboration and that we will have the chance to work together for a very long time!
Working with Localex Translation is always a very positive experience, due to the professionalism and politeness of their staff. Their deadlines are realistic and are always eager to provide any clarifications, when needed. In addition, their rates are fair and their payment dates punctual. As a translator, working with them and interacting with their staff is a joy. I highly recommend Localex Translation to any linguist.
It has been a great pleasure working with Localeks. Very friendly, yet professional team members who are always responsive and ready to go the extra mile to make sure everything is clear for their vendors. I can always feel confident that I’m giving the best I can and meeting my deadlines thanks to their friendly support and continuous help.